Welcome to Mappr.co, your ultimate destination for exceptional maps, stunning global photography, and inspiring travel recommendations.
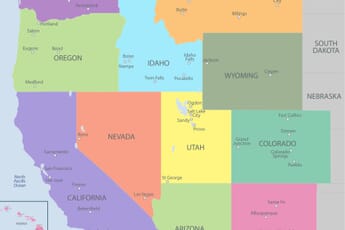

Geography Quizzes
NEW: General Geography Quiz 📚🗺
SCORE 60%+ UNDER 4 MINUTES AND GET A CERTIFICATE OF ACHIEVEMENT!
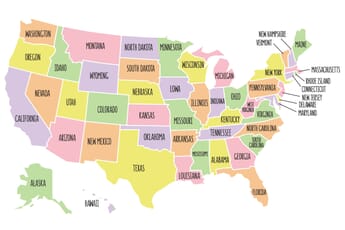
Looking to test your knowledge of US geography? Take our USA 🇺🇸 States Map Quiz to put your skills to the test and see if you can locate all 50 states!
And if you’re feeling worldly, challenge yourself with our European 🇪🇺 Capital Cities Quiz and then broaden your horizons further with our Guess the World 🌍 Flags 🎌 Quiz!
Interesting Facts from Around the World
- The 20 Largest National Parks in the US

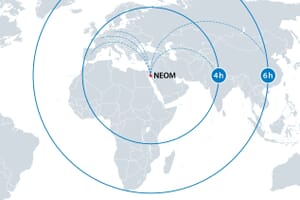
- Where is Neom? A Glimpse into Saudi Arabia’s Futuristic City
- Most Densely Populated Cities in the World

- Safest Cities in Africa: 2023’s Top Secure Destinations for Travelers Revealed!

- 20 Most Visited Countries by Digital Nomads in 2023

- 20 Biggest Earthquakes in the World

Latest Travel Destinations
- 🇰🇷💎 33 Hidden Gems in South Korea Best to Visit This Summer

- 🇳🇴💎 33 Hidden Gems in Norway Best to Visit This Summer

- 🇳🇱💎 33 Hidden Gems in the Netherlands Best to Visit This Summer

- 🇺🇸💎 33 Hidden Gems in the United States Best to Visit This Summer

- 🇦🇺💎 33 Hidden Gems in Australia Best to Visit This Summer

- 🇨🇦💎 33 Hidden Gems in Canada Best to Visit This Summer








Flag Maps and Meanings

















Guides, Facts, and Travel
- Buying Guides (16)
- Interesting Facts (53)
- Mappr News (2)
- Travel and Tourism (29)